3.7 TCP 的拥塞控制
经典的 TCP 拥塞控制
与流量控制类似,发送方会维护一个被称作 拥塞窗口(Congestion Window,cwnd) 的变量,其同样限制了 TCP 能够向网络中发送流量的速率。具体为要求满足未被确认的数据量不超过 cwnd 与 rwnd 的较小值。
TCP 使用 丢包事件 作为网络拥塞的指示。丢包事件可能由超时计时器超时引发,也可能由收到 3 个冗余 ACK 触发。前者被视为网络中出现了拥塞,而后者只被视作出现了 轻微 拥塞,此时 TCP 会停止增加或缩减 cwnd 的大小。TCP 将对未确认报文段的 ACK 当作网络正常运作无拥塞的指示,会根据这些 ACK 到来的速度增加 cwnd 的值。
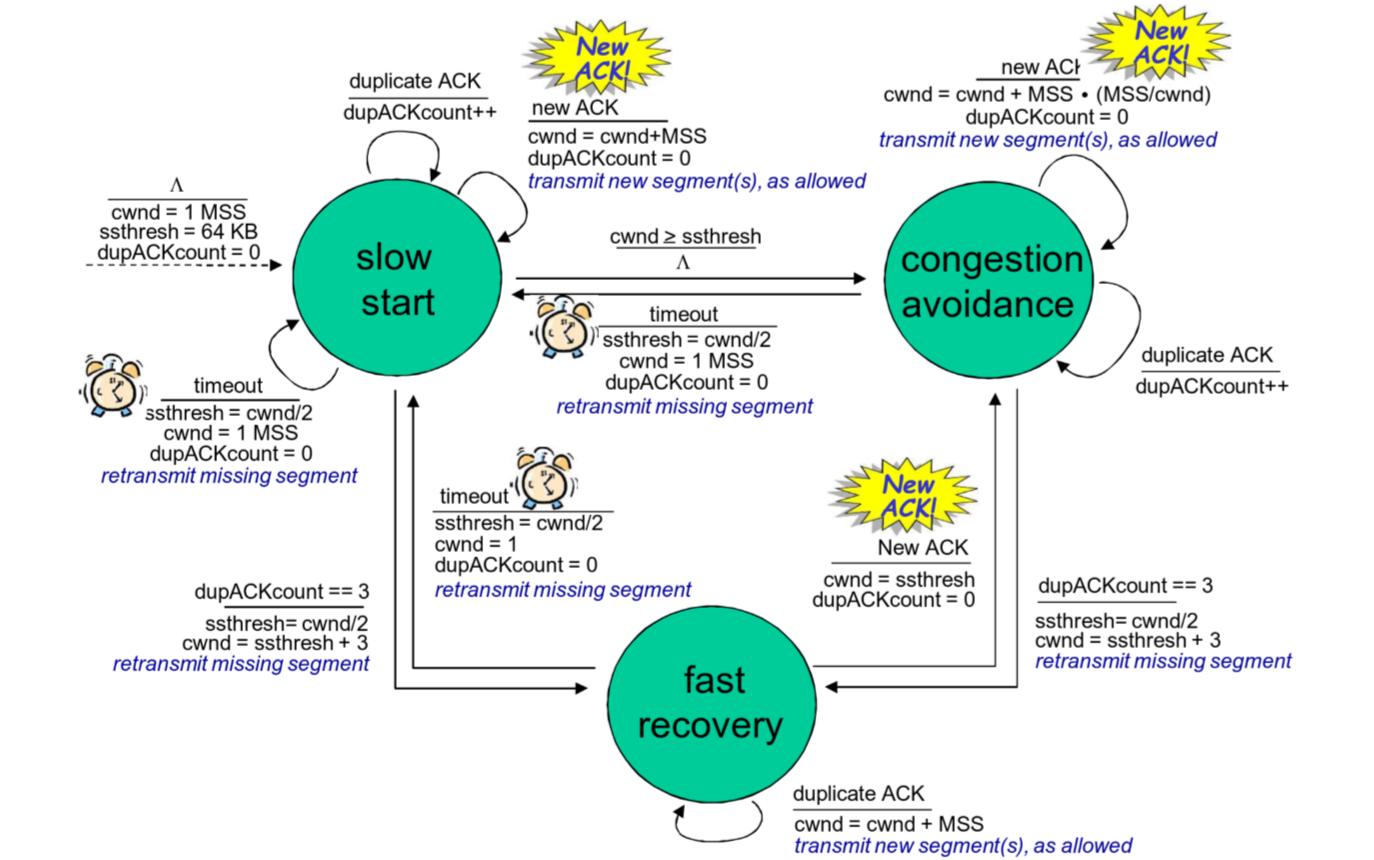
经典的 TCP 拥塞控制算法包含三个主要部分:慢启动、拥塞避免与快速恢复。其中快速恢复为可选项,在 TCP 的一种早期版本 TCP Tahoe 中就没有实现快速恢复;后来的 TCP Reno 实现了快速恢复。除了实际控制发送速率的 cwnd 之外,该算法还会额外维护一个可能指示会发生拥塞的警戒阈值 ssthresh。
慢启动
TCP 连接初始建立时处于慢启动阶段,cwnd 初始为一个较小值,一般为一个 MSS。
每当收到一个正常的,对未确认报文段的 ACK 后,TCP 认为目前网络没有发生拥塞,cwnd 增加一个 MSS。在这种情况下,在每一轮 RTT 过后,如果所有报文段都正常被确认没有发生超时,则 cwnd 将翻倍。如此 cwnd 随着 RTT 的轮数呈现指数增长趋势。
直到发生丢包事件时,根据该事件所指示的拥塞情况的不同:
- 若为超时丢包,设置
cwnd为初始值,ssthresh为触发超时时的cwnd的一半,重新进入慢启动阶段。 - 若为三次冗余 ACK 触发的丢包,触发快速重传,设置
ssthresh为触发超时时的cwnd的一半。但由于拥塞不严重,cwnd设置为ssthresh加 3 个 MSS 的值,并进入 快速恢复 阶段。
当 cwnd 不小于 ssthresh 时,可以认为将要触发拥塞,进入 拥塞避免 阶段。
拥塞避免
在该阶段中,TCP 将采用更为谨慎的的方式增加 cwnd:在未触发丢包事件时,每轮 RTT 后 cwnd 只增加一个 MSS。即设本轮发送了 cwnd 增加
当触发丢包事件时,其行为与 慢启动 阶段相同。
快速恢复
快速恢复阶段是针对部分报文丢失(如少量丢包)的优化机制,其核心目标是在检测到拥塞时快速调整发送速率,避免因过度降低窗口导致吞吐量骤降。进入该阶段不会导致 cwnd 被重置为初始值,而是仅将窗口减半(当然有对最初收到的三个冗余 ACK 的补偿),保留部分容量。
在该阶段中,每当收到同样的冗余 ACK,cwnd 的值增加一个 MSS。直到收到新的 ACK 时(这表明丢失的报文段已经被收到),将 cwnd 设为 ssthresh 并进入拥塞避免阶段。若在这一过程中出现了超时,则执行与 慢启动 和 拥塞避免 类似的操作并进入 慢启动 状态。
总结
这是对 TCP 拥塞控制算法的状态机描述:
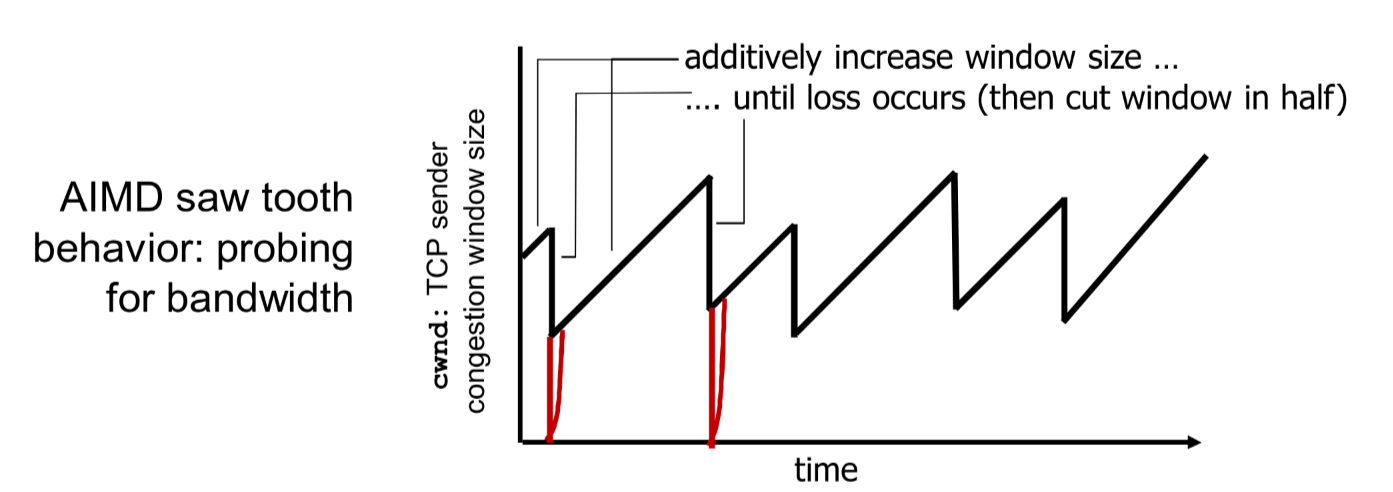
我们尝试模拟这一过程观察一下 cwnd 的变化规律可以发现:TCP 线性增加拥塞窗口的大小,直到遇到丢包事件时,将其乘性减半。正因此 TCP 被称作 加性增、乘性减 的控制方式,如下图所示:
吞吐量
我们尝试考察一下在这种拥塞控制机制下运行足够长时间后,TCP 连接的平均吞吐量如何计算。
由于慢启动阶段持续时间很短,其对于平均吞吐量的影响可以忽略。我们不妨考虑某条理想化的通信链路,其总会在拥塞窗口大于
改进的的 TCP 拥塞控制方法
一般而言,在短时间内,两对主机之间的吞吐量会保持相对稳定。传统的 TCP Reno 拥塞控制算法在拥塞控制阶段增加拥塞窗口的策略相对保守,不利于提高链路的利用率以提升吞吐量。目前有多种改进的拥塞控制算法:
拥塞窗口增长方法的改进:TCP CUBIC
一种改进方法是改进探测分组的最大发送速率的策略。如果在出现丢包的链路处拥塞的变化状态不大,可以考虑使用一种能使发送速率迅速接近先前未发生丢包时的发送速率,在接近该速率后使用更谨慎的方法探测带宽的算法。TCP CUBIC 就是基于该思想提出的算法,其与 TCP Reno 的唯一区别在于拥塞避免阶段时增加拥塞窗口的算法:与 TCP Reno 随着 RTT 数线性增加拥塞窗口不同,TCP CUBIC 如其名字所示依照一个三次函数增加拥塞窗口。
具体而言,我们设 cwnd 的值,cwnd 重新达到 cwnd 的值,当检测到拥塞后,cwnd 首先设为
式中的
TCP CUBIC 与 TCP Reno 在具有稳定带宽的链路的性能如图:
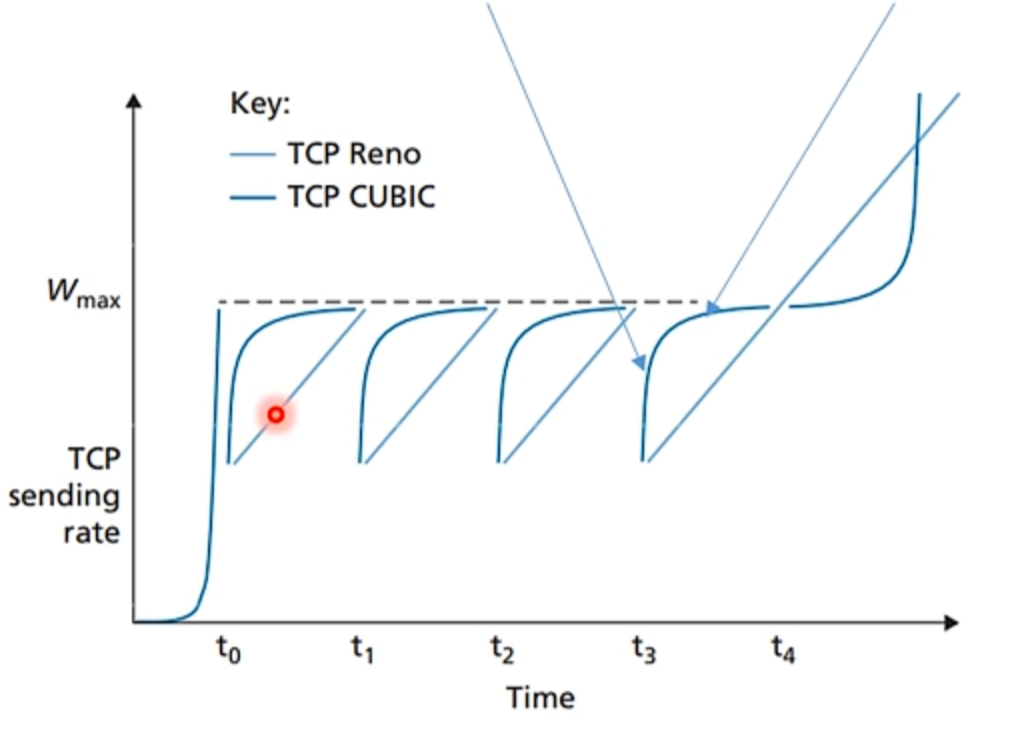
可以发现 TCP CUBIC 因其三次函数的凹-凸特性使其在远离
此外,为了与传统的 TCP Reno 公平竞争(见下文公平性),当估计的窗口增长速率低于传统 Reno 的线性增长(即
基于时延的拥塞控制:TCP Vegas
TCP Reno 类算法对带宽利用率不高的根本原因在于这类算法使用拥塞事件来探测可用带宽,而没有关于链路带宽的先验知识。这样会导致拥塞窗口反复降低,尤其是当分组连续丢失时,对发送方的发送速率惩罚过大,才导致带宽利用率下降。因此,TCP Vegas 采用通过测量报文段的 RTT 来探测网络中的拥塞状况,以期在丢包出现前主动检测拥塞。具体如下:
连接建立时默认处于慢启动阶段,测量该连接的最小 RTT 记为 BaseRTT,代表无拥塞时的延迟。随后,以 两个 RTT 为周期倍增 cwnd。一个 RTT 增加拥塞窗口。另一个 RTT 用于测量当前实际吞吐量与期望吞吐量的差值 Diff:
一旦二者差值过大(满足 cwnd 设为原来的
推荐值为
该算法的性能图如下:
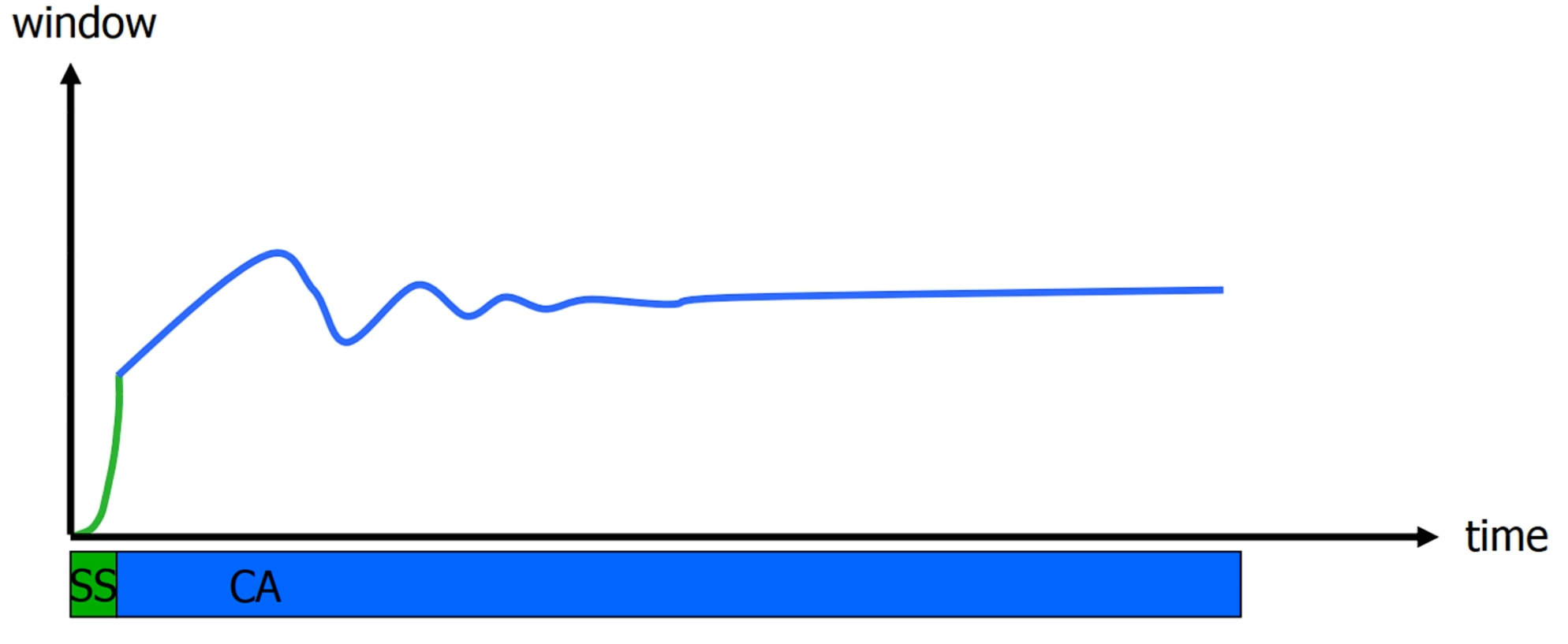
可以发现与 TCP Reno 相比,TCP Vegas 带来了更细粒度、更温和的速率调节,使得传输速率总是靠近可用带宽。然而其也对 RTT 的变化较为敏感,这导致其极有可能将传输路径变化导致的 RTT 波动误认为拥塞并减少拥塞窗口;与 TCP Reno 或 TCP CUBIC 共存时,其也经常处于下风。因此 TCP Vegas 适合单独部署在低延迟、低丢包网络(如数据中心)中,而不适合部署在互联网中。
基于网络辅助明确拥塞通告的拥塞控制
还有一种检测拥塞的方法便是让网络层直接提供关于拥塞的反馈信息,这类信息比超时等拥塞事件来得更早,与前面介绍过的拥塞控制算法协同效果会更好。
明确拥塞通告(Explicit Congestion Notification,ECN) 对 TCP 与 IP 作出了一定修改,使得这两个协议的报文可以携带拥塞指示的标志位:在 IP 报文(见4.3 IP)引入了 ECT 与 CE 两个标志位,前者指示端主机是否支持 ECN;后者由路由器置位,当某台路由器经历拥塞时,会将经过该路由器的报文的 CE 标志置位。在 TCP 报文(见 TCP 报文段结构)中引入了 ECE 与 CWR 标志位,接收端接收到 (ECT, CE) = (1,1) 的拥塞指示报文时,会将回送的 ACK 报文中的 ECE 标志位置位,通知发送段链路发生了拥塞。发送方接收到对应报文后,会执行对应的拥塞避免动作,并将发送给接收方的报文的 CWR 标志位置位,指示接收方回送的拥塞通知已经收到。接收方接收到 CWR 标志位置位的报文后就会停止发送 ECE 标志位置位的报文。接收方在一个 RTT 中只会执行一次拥塞避免动作。
公平性
经典的 TCP 拥塞控制算法是公平的,在每台主机都具有相同的 TCP 连接数,MSS 与 RTT 相同的理想情况下,对于多条竞争瓶颈链路传输带宽的连接,其总是趋于将瓶颈链路贷款平等分给各条竞争连接。
我们不妨假设如下理想化情景:两条 TCP 连接竞争一条链路容量为 的瓶颈链路。这两条连接具有相同的 MSS 与 RTT。
考虑下面的曲线。理想情况为两线交点,即两条连接平均占满瓶颈链路带宽。
假设在某时位于 A 点,由于链路没有占满,两条连接沿着 A -> B 方向增加拥塞窗口,直到超出链路容量产生丢包事件,状态会立刻转移至 C 点,再继续沿着 C -> D 方向移动......以此类推,最终状态会趋向于理想情况附近的某个位置。
然而在现实中这些条件总是无法得到满足,考虑如下情况:
- 具有较小 RTT 的链路可以更快的增加拥塞窗口从而更快抢到可用带宽。
- 如果链路中有 UDP 流量,由于 UDP 没有拥塞控制机制不会主动降低传输速率,在 TCP 看来 UDP 是不公平的,可能导致 UDP 流量压制 TCP 流量。
- 某台主机建立了很多条 TCP 连接。由于 TCP 按照 连接 公平均分链路带宽,则建立了更多 TCP 连接的主机可以占据更多流量。